Flows
Overview
A flow is the basis of all work with LLM Stack. It consists of an input, an output and 1 or more tasks.
Chaining reusable components for an LLM workflow
Everything as Flow: All LLM work can be described in a workflow or flow for short. Here are some examples:
ChatGPT
flowchart LR
LLM
Doc Summarization
flowchart LR
FileLoader --> LLM
DocumentParser
flowchart LR
FileLoader --> LLM
Retrieval Augmented Generation (RAG)
flowchart LR
Embeddings --> VectorStoreRetriever --> LLM
This is implemented at Q&A Example.
RAG with translation
flowchart LR
LLM1(LLM for Translation) --> Embeddings --> VectorStoreRetriever --> LLM
Flow Types
Below are some common flow types that can be implemented with LLM Stack. These flow types have associated sample apps.
But users are not limited to only these flow types.
VectorStoreManagement
A flow designed to create and update a vector store that can be reused by other flows, such as QuestionAnswering or Search.
Conceptual flow diagram:
graph LR
Input --> ContentLoader --> TextSpliter --> EmbeddingsModel --> VectorStoreBuilder --> Output
Examples
Vector Store Builder from a website
| type: flow
name: Sample Vector Store Builder from a website
description: Sample Vector Store Builder from a website
flow_type: VectorStoreManagement
input:
- name: url
description: The website address to load data from
type: string
required: false
tasks:
- name: WebLoader
description: Load data from a web page or from remote files
type: schema.task.content_loader.WebLoader
input:
recursive: true
url: $inputs.url
max_urls: 10
start_selector_type: class_name
start_element: content
task_config:
retries: 0
timeout_seconds: 30
persist_result: true
cache_result: true
cache_expiration: 5m
- name: CharacterTextSplitter
description: Split text into chunks
type: schema.task.text_splitter.CharacterTextSplitter
input:
documents: $WebLoader.output
separator: "\n## "
chunk_size: 300
chunk_overlap: 20
task_config:
retries: 0
timeout_seconds: 30
persist_result: true
cache_result: true
cache_expiration: 5m
- name: EmbeddingsModel
description: Embeddings Embeddings
type: schema.task.embedding.EmbeddingsModel
input:
mode: documents
documents: $CharacterTextSplitter.output
provider: openai
model_name: text-embedding-ada-002
batch_size: 32
task_config:
retries: 3
timeout_seconds: 90
persist_result: true
cache_result: true
cache_expiration: 5m
- name: QdrantBuilder
description: Build a vector store
type: schema.task.vector_store_builder.QdrantBuilder
input:
embeddings: $EmbeddingsModel.output
collection_name: test_collection
task_config:
retries: 1
timeout_seconds: 10
persist_result: true
cache_result: false
cache_expiration: ""
output:
- name: collection_name
value: $QdrantBuilder.output
- name: documents
value: $CharacterTextSplitter.output
|
QuestionAnswering
A flow specifically developed to support Question Answering applications, such as the IM8 Q&A bot. It leverages an LLM to understand questions and provide accurate and relevant answers based on provided context.
Conceptual flow diagram:
graph LR
Input --> EmbeddingsModel --> VectorStoreRetriever --> LLM --> Output
Examples
Question Answering from a web page
| type: flow
name: "My Website Q&A Bot"
flow_type: QuestionAnswering
input:
- name: the_url
description: The URL of the website to load content
type: string
default: https://www.washingtonpost.com/technology/2023/05/16/sam-altman-open-ai-congress-hearing/
- name: the_question
description: The question to ask on the website content
type: string
required: true
tasks:
- name: MyWebPageContentLoader
description: Load text content from a webpage
type: schema.task.content_loader.WebLoader
input:
url: $inputs.the_url
task_config:
retries: 3
timeout_seconds: 10
cache_result: true
cache_expiration: 24h
- name: MyLLM
description: Use LLM to generate answer based on retrieve documents
type: schema.task.llm.ChatLLM
input:
messages:
- type: system
content: |
You are Q&A Chat Bot. Use the provided context to answer question.
If you don't know the answer, just say "Sorry, I don't know the answer to this", don't try to make up an answer.
- type: user
content: |
Context:
{{ MyWebPageContentLoader.output[0].content }}
Question: {{ inputs.question }}
provider: openai
model_name: gpt-3.5-turbo
temperature: 0
max_tokens: 256
task_config:
retries: 1
timeout_seconds: 30
cache_result: true
cache_expiration: 24h
output:
- name: llm_response
value: $MyLLM.output
|
Question Answering from an existing vector_store
| type: flow
name: Sample Question Answering Flow using existing vector store
description: Sample Question Answering Flow using existing vector store
flow_type: QuestionAnswering
input:
- name: question
description: Question from user
type: string
required: false
tasks:
- name: EmbeddingsModel
description: Embeddings
type: schema.task.embedding.EmbeddingsModel
input:
mode: query
documents: null
provider: openai
model_name: text-embedding-ada-002
batch_size: 32
query: $inputs.question
task_config:
retries: 3
timeout_seconds: 90
persist_result: true
cache_result: true
cache_expiration: 5m
- name: QdrantRetriever
description: Retrieve documents from a vector store
type: schema.task.retriever.QdrantRetriever
input:
embeddings: $EmbeddingsModel.output
collection_name: test_collection
task_config:
retries: 1
timeout_seconds: 30
persist_result: true
cache_result: true
cache_expiration: 5m
- name: ChatLLM
description: Use LLM to generate answer based on retrieve documents
type: schema.task.llm.ChatLLM
input:
messages:
- type: system
content: >
You are a Question Answering Bot. You can provide questions based on given context.
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
Always include sources the answer in the format: 'Source: source1' or 'Sources: source1 source2'.
- type: user
content: |-
Context:
{%- for doc in QdrantRetriever.output %}
Content: {{ doc.content }}
Source: {{ doc.metadata.source }}
{%- endfor %}
Question: {{ inputs.question }}
provider: openai
model_name: gpt-3.5-turbo
temperature: 0
max_tokens: 512
task_config:
retries: 1
timeout_seconds: 30
persist_result: true
cache_result: true
cache_expiration: 5m
output:
- name: llm_response
value: $ChatLLM.output
- name: documents
value: $QdrantRetriever.output
|
Search
A flow dedicated to supporting Search applications, particularly site search. It enables users to search for information within a specific domain or dataset, returning relevant results based on the provided query.
Examples
TBD
Summarization
A flow aimed at generating concise summaries of long texts. It uses an LLM to distill the key information and main points from a given text.
Examples
Summarizing a web page
| type: flow
flow_type: Summarization
name: Sample summarizer from a web page
input:
- name: the_url
description: The URL of the website to load content
type: string
default: https://www.washingtonpost.com/technology/2023/05/16/sam-altman-open-ai-congress-hearing/
tasks:
- name: MyWebPageContentLoader
description: Load text content from a webpage
type: schema.task.content_loader.WebLoader
input:
url: $inputs.the_url
save_path: /tmp
task_config:
retries: 3
timeout_seconds: 10
cache_result: true
cache_expiration: 24h
- name: SampleRecursiveTextSplitter
description: Recursively split text into chunks
type: schema.task.text_splitter.RecursiveCharacterTextSplitter
input:
documents: $ContentLoader.output
separators: ["\n\n", "\n"]
chunk_size: 4000
chunk_overlap: 0
task_config:
retries: 0
timeout_seconds: 5
persist_result: true
cache_result: true
cache_expiration: 5m
- name: MyLLM
description: Use Summarize LLM to generate summary based on text
type: schema.task.llm.SummarizeLLM
input:
documents: $SampleRecursiveTextSplitter.output
provider: openai
model_name: gpt-3.5-turbo
temperature: 0
max_tokens: 4096
task_config:
retries: 0
timeout_seconds: 120
persist_result: true
cache_result: true
cache_expiration: 5m
output:
- name: summary
value: $MyLLM.output
|
Classfication
A flow to classify text into predefined categories or labels. This can be used for tasks such as spam detection, topic classification, sentiment analysis, and more.
Examples
TBD
Flow Input is a JSON object containing parameter values for the flow.
Given the following flow described in e2e-qna-example.md
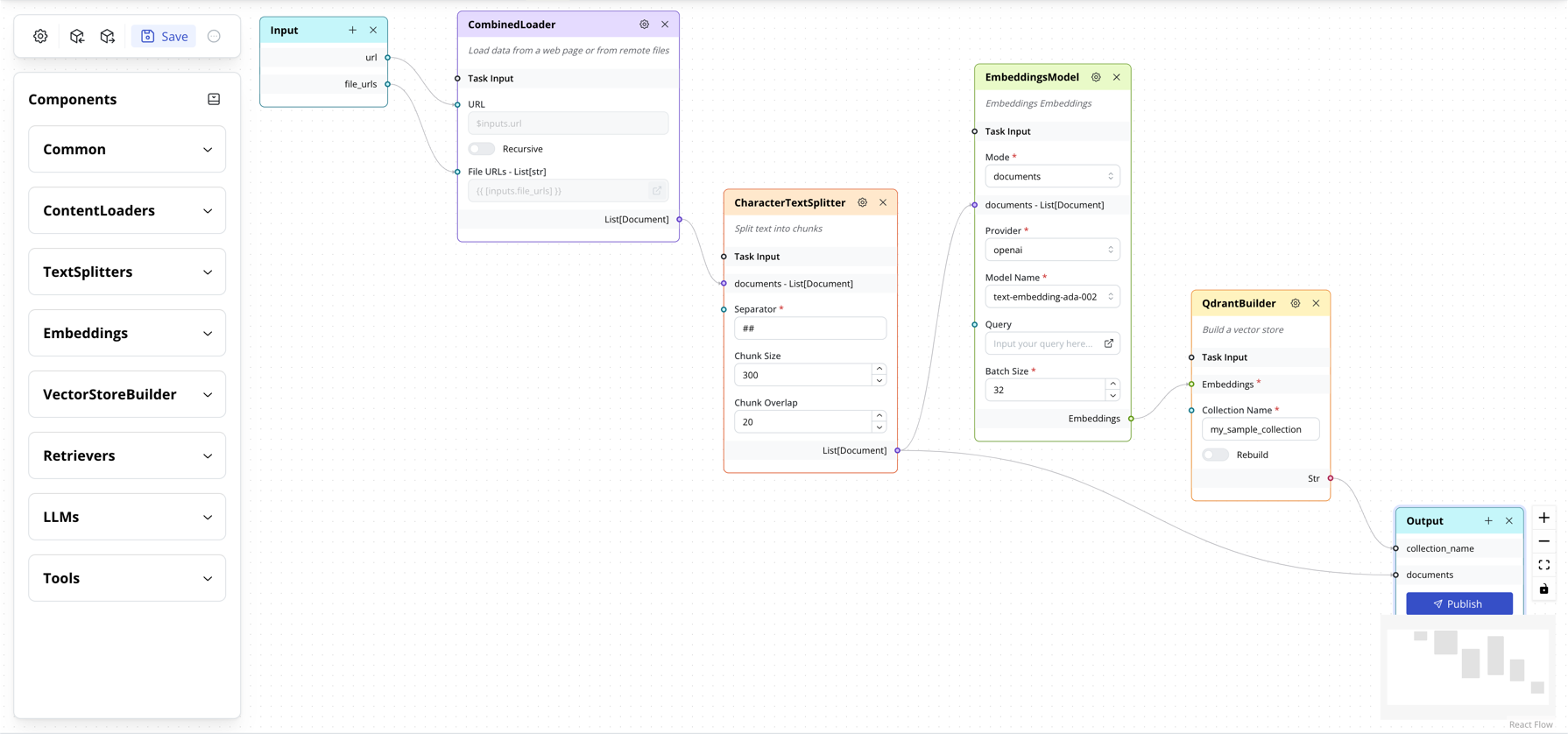
There are 2 input parameters (url, file_urls) with 4 tasks.
Input to a task can be set using the flow's input parameters that are linked to the task. This is the recommended approach for a clean API.
However, there can be scenarios where an API user wants to modify a task input parameter even though it was not linked to a flow's input parameter.
To support this, we allow task parameters to be specified directly in the flow input. Below are 2 examples which result in the setup.
Example 1: Using flow's input parameter
{
"flow_id": "<flow_id>",
"inputs": [{
"url": "https://www.example.com",
"file_urls": [
"https://docs.google.com/document/d/example"
]
}]
}
Example 2: Using task's input parameter
{
"flow_id": "<flow_id>",
"inputs": [{
"file_urls": [
"https://docs.google.com/document/d/example"
],
"CombinedLoader": {
"url": "https://www.example.com"
}
}]
}
Further customization
By using task input parameter, users can further customize the input to the task.
For example, the CombinedLoader task has a recursive parameter that is not exposed as a flow input parameter. This can be set by using the task input parameter.
{
"flow_id": "<flow_id>",
"inputs": [{
"file_urls": [
"https://docs.google.com/document/d/example"
],
"CombinedLoader": {
"url": "https://www.example.com",
"recursive": false
}
}]
}
Flow Output
Flow Output is a JSON object containing the output values of the flow.
In the sample flow above, there are 2 output parameters (collection_name and documents).
Output parameters can take values from the output of any tasks in the flow, although usually the last task's output is most important.
However, there can be scenarios where an API user wants to have additional output parameter values even though it was not defined as a flow's output parameter.
To support this, we allow output parameters to be specified in the API request body.
For example, the documents output parameter defined in the flow may contain too many documents. Below request body shows how an API user can modify the output to limit the number of documents returned.
{
"flow_id": "<flow_id>",
"inputs": [{
"url": "https://www.example.com",
"file_urls": [
"https://docs.google.com/document/d/example"
]
}],
"outputs": {
"documents": "{{ CharacterTextSplitter.output[:10] }}"
}
}